因为朋友要写开题报告,托我看看CoralCDN的论文,我觉得既然看了,就不如看的仔细点。于是有了这片文章。
Coralcdn是一种p2p方式的web内容分发网络(content delivery network),不过也有人叫它content distributed network,他的特点和使用方法就不说了,想要了解的google一下就ok了。下面我希望能够简单清楚介绍一下coralcdn的工作机制。当然看原始的论文会更清楚一点,而且网站上面还有一个ppt。
Coral的Indexing机制
coralcdn底层的DHT网络被称之为coral,coral使用一种扩展的DHT方式Indexing机制,DSHT(distributed sloppy hash table),声称较好的解决了DHT overlay中的locality的问题。不同于经典的DHT方式,coral首先对所有overlay中的node的网络状况进行一个评估, 然后按照RTT的时间代价自然划分为几个等级(coral里称之为按照网络的diameter划分),默认的是3级,L2(<20ms),L1(<60ms),L0(剩余的所有节点)。完整的NodeID的节点空间仍然是由SHA-1生成的160bit,但是查找和放置的时候,不是在整个NodeID空间上查找,而是优先在L2上的节点进行DHT查找,L2 层中找不到合适的节点再去L1层中查找,最后才是L0层。这样做的显然是考虑了locality,但是查找的次数应该对于一般DHT方式的查找次数。所以具体孰优孰劣还是要看实验数据,但是从直观感觉上还是coral要节省时间一点。不过DHT只需要维护一个DHT空间,而coral则需要维护三个,显然在节点加入或离去的时候,系统地自平衡代价也要大一点的。(不知道coral的作者们又没有考虑这个问题,:))
coral的组成部分
coral的主要组成部分有两个:Coral DNS Server——dnssrv;Coral Httpproxy——CoralProxy
dnssrv
在client查找coralize URL 的时候,dnssrv返回Proxy的IP地址,这些proxies都是在一个合适的cluster(就是前面说的L2、了L1、L0层)之中,同时确保来自于相同client的DNS请求不会离开这个cluster。下面我们就来看看Coral怎样实现。所谓的coralize的URL就是加上.nyud.net:8090,但是这实际上是为了方便而采取的一个缩写,完整的应该是.http.L2.L1.L0.nuycd.net,每一个dnssrv都是解析这个域名的nameserver。同时Coral假设dnssrv的了Locality就是WebBrowser的Locality。在每次请求中,dnssrv返回两个数据集,对于IP的proxy地址集,对于name's domain的nameserver。而且client和dnssrv之间的RTT如果在level-i层,那么dnssrv只返回那些在同一个level上Coral node的地址。对于proxy,返回的短的TTL,对于L2、L1是30s,L0是60s。dnssrv同时会在获得DNS授权的数据中查找,并把client锁定到合适的cluster上面。并且给这些nameserver一个比较长的TTL(1h)。对那些长于L1时间的client,dnssrv返回的是域L0.nyucd.net的nameserver,长于L0时间的client,dnssrv返回的是域L1.L0.nyucd.net的nameserver。
Coral Http Proxy
Coral设计主要是考虑低延迟、高系统吞吐以及对于源服务器的负载减轻。类似于freenet走过必留痕迹的策略,每个CoralProxy都尽可能的“拉”网页来,如果client请求的URL不再本地cache 中,则他们就会在Coral中查找(Coral的底层就是扩展kademlia), 然后再DSHT中插入一个references,告知系统自己有这个cache,保存的时间为20s,如果这个proxy完整的得到了文件,就会告知系统他会保存这个更长的时间(比如1h)。
Coral的存贮方式:Sloppy Storage
据称这种方式减少了hot-spot和tree saturation现象。在本来的kad中,key和node之间的关系是对应的,在插入时,有两个阶段,第一个阶段叫“forward”(相当于正常的kad插入),需要在node处于full或者loaded状态下需要做相应的调整。对一个node如果一个key存储了l(=4)就被称为full;
在一分钟之内如果一个node上的一个key被请求bata(=12)次,则称nodeloaded。
这时,就需要把key/value放在更远的node上。
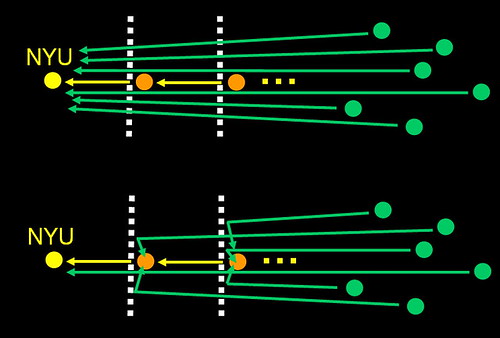
第二个阶段“reverse”,根据“forward”阶段的结果client试图插入value到最远的节点,如果“forward”这个操作失败,那client就会稍微回退一点(文章中叫做pops stack),把这个值放到次远的节点上(参见上图)。
取回值的操作其实就是插入操作的逆向操作,这里就不再赘述。
Coral中的层次式的操作
这个在前面已经叙述了,这里在解析清楚几个概念再加一张图。Cluster就是Coral中的层次,其中每一对节点之间平均的RTT要小于一个阚值,就可以成为同在一层(Cluster)中。层次式的查找和插入的意思首先在RTT小的Cluster中进行,如果失败,则转入下一层中。参见下图。
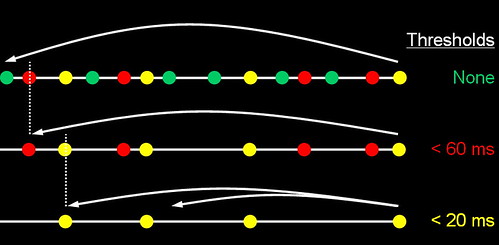
为了实现这种层次式的操作方式,每次Coral RPC都需要返回发送者的Cluster的信息。
好了到这里,基本上的内容都差不多了。最后想提一下CoralCDN的代码量。Coral是14,000行C++写成的,dnssrv2,000行,HttpProxy4,000行代码。看起来还是很复杂的:)



没有评论:
发表评论